[DB] 분산 DB, 파티셔닝 (partitioning ), 샤딩 (sharding)
파티셔닝(단편화) 란?
저장해야 하는 정보가 많은 대규모 시스템의 경우 하나의 DB에 모든 정보를 저장해서는 제대로 된 응답성을 기대할 수 없다.
read가 많이 발생하든, write가 많이 발생하든 DB 저장하는 정보가 많을 수록 스캔 속도도 느려지고, 요청이 많은 경우 큐에 작업이 쌓이면서 응답도 느려진다.
그래서 DB를 여러대 운용해서 응답을 좀 분산해보자, 라는 생각을 하게 되는데, 가장 쉽게 생각해 볼만한건 Master DB의 데이터를 복제한 Slave DB를 두고, read를 분산하는 것이다. 스캔 속도는 그대로겠지만 요청을 분산할 수 있다.
그러나 이 방법은 write는 분산되지 않는다. Master에 write가 발생하면 이를 Slave에 복제 해줘야 하므로, 복제하면서 같은 내용의 write가 발생하기 때문이다.

- 그래서 아예, 분산 DBMS는 위처럼 여러 개의 DB가 모두 같은 전체 데이터를 가지고 있고 응답만 분산하는 형태가 아니라, 각각의 DB가 데이터를 일부분씩 나눠 가지고 있도록 구성할 수 있다.
- 이 것이 파티셔닝(단편화)이다.
- [X테이블은 A디비, Y테이블은 B디비] 형식으로 나눠 가지는건 파티셔닝이 아니다.
- 이렇게 되면 단순히 다른 DB에 다른 테이블이 존재하는 것. 테이블 간 Reference 등이 불가능한 별도의 DB다.
- X테이블에 트래픽이 몰리면 결국 한 DB에 트래픽이 몰리게 된다.
- [X테이블의 일부분은 A디비, X테이블의 다른 일부분은 B디비] 형식으로 테이블을 나눠 가지는 것이 파티셔닝이다.
- 그리고 DB에 저장되는 데이터는 결국 테이블 안에 들어있는 데이터이기 때문에, 테이블을 잘라서 일부분씩 나눠 가지게 된다.
- 테이블을 나눠 가지는 방식에 따라 파티셔닝은 크게 수평 단편화와 수직 단편화로 나눌 수 있다.
RAID와는 다르다. RAID는 DB와 독립적인 개념으로 디스크를 여러 개 사용하는 거고, 이 여러개의 디스크가 결국 논리적으로는 하나의 디스크 처럼 보이게 하는 기술이다. 즉, DB에서 사용할 때는 하나의 DBMS 내에서 디스크를 여러 개 사용하는거라고 볼 수 있다. 반면 파티셔닝은 DB를 여러 개로 분산하는 것이다. DB는 현재 디스크가 RAID인지는 모를 수 있고, partitioning에 대해서는 반드시 알 수 밖에 없다.
수평 단편화 = 샤딩 (sharding = horizontal partitioning)
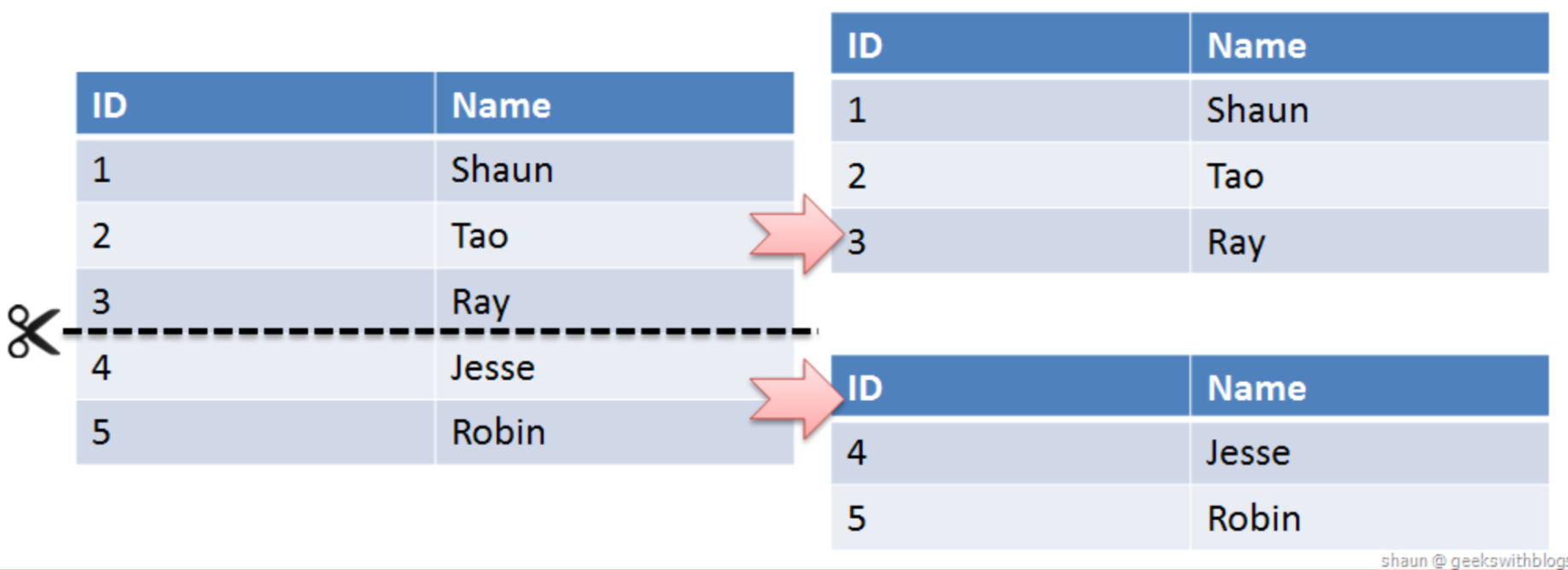
샤딩은 결국 테이블을 수평으로 쪼개는 것이기 때문에, 어떤 DB에 해당 데이터가 있을지 찾아갈 수 있어야 한다. 요청 마다 모든 DB를 뒤질 수는 없으니까.
해당 데이터가 존재하는 DB를 잘 찾아낼 수 있도록, 그리고 각 DB에 공평하게 row들이 분배되도록 Key를 잘 설계하는 것이 중요하다.
2019/01/18 - [DB] - 확장성 해싱 VS 선형 해싱 : Shard key
수직 단편화 ( vertical partitioning )

일반적으로 엔티티를 분리할 때 처럼, 컬럼을 나눠 새로운 테이블로 만들어서 나눠갖는 것.
이렇게 나누는 경우는 보통 어떤 컬럼이 빈번하게 참조될 때다. 왜냐면 한 row가 작아서 상대적으로 여러 row가 캐시에 올라갈 수 있고, 이는 즉 해당 컬럼의 여러 데이터가 캐시에 올라갈 수 있다는 말이 되어 Hit rate가 좋아진다.
참고
'RDBMS > DB Basics' 카테고리의 다른 글
| DB 이중화 / 클러스터링 (0) | 2020.09.23 |
|---|---|
| 7장. 릴레이션 정규화 (0) | 2018.04.12 |
| 6장. 물리적 데이터베이스 설계 : 인덱스 기본 원리 (0) | 2018.04.06 |
| 5장. 데이터베이스 설계와 ER 모델 (0) | 2018.01.07 |