7장. 릴레이션 정규화
ER 스키마 >> 릴레이션 사상
간단한 요소에서 복잡한 요소 순으로 사상한다.
- 단계 1: 정규 엔티티 타입
- 단계 2: 약한 엔티티 타입
- 단계 3: 2진 1:1 관계 타입
- 단계 4: 정규 2진 1:N 관계 타입
- 단계 5: 2진 M:N 관계 타입
- 단계 6: 3진 관계 타입
- 단계 7: 다치 애트리뷰트
정규화 Normalization
정규화란 무엇이고 왜 하나?
- 정규화란? 릴레이션 스키마를 함수적 종속성과 기본키를 기반으로 분리하는 것.
- 왜 하나?
- 1. 데이터 중복 최소화
- 2. [수정, 삽입, 삭제] 이상 최소화 (보통 데이터 중복 -> 갱신 이상으로 이어지는 경우가 많음.)
- 세 가지 갱신 이상
- 수정 이상 : 데이터가 중복되어 모든 항목을 일괄 수정하지 않으면 데이터 불일치가 발생
- 삽입 이상 : 불필요한 정보를 함께 저장하지 않고는 어떤 정보를 저장하는 것이 불가능
- 삭제 이상 : 유용한 정보를 함께 삭제하지 않고는 어떤 정보를 삭제하는 것이 불가능
좋은 RDB 스키마를 설계하는 기준은,
정보의 중복과 갱신 이상이 생기지 않도록 하고, 정보의 손실을 막으며, 실세계를 훌륭하게 나타내고, 애트리뷰트들 간의 관계가 잘 표현되는 것을 보장하며, 어떤 무결성 제약조건의 시행을 간단하게 하며, 아울러 효율성 측면도 고려하는 것.
먼저 갱신 이상이 발생하지 않도록 노력하고, 그 다음에 효율성을 고려함.
결정자와 함수적 종속성
결정자 (determinant)
- 쉽게 생각해서 A로 검색했을 때 B가 모두 같은 값이 나온다면, A는 B의 결정자다.
- 사원번호 4257로 검색하면 이름 "가나다"만 나온다.
- 사원번호 4257인 사원의 이름이 "가나다"인 동시에 "이말년"일 수는 없음.
- 따라서 사원번호는 이름의 결정자다.
- 즉 A값에 대응되는 B가 꼭 하나여야 한다는 것인데
- 반대로 B값에 대응되는 A는 여러개여도 상관 없다.
- 사원번호 4257 이름 "가나다"
- 사원번호 3215 이름 "가나다"
- 결정자 A는 여러 애트리뷰트로 구성될 수 있음 (복합키 같이)
- 결정자는 추후 분해된 릴레이션의 기본키가 될 수 있다.
함수적 종속성
- A가 B의 결정자이면 B가 A에 함수적으로 종속한다. 라고 말함.
- 완전 함수적 종속성
- 해당 릴레이션의 모든 결정자를 사용해야만 1가지 값으로 결정되는 경우를 완전 함수적 종속성
- 모든 결정자를 써야만 함수적으로 종속하는 경우
- 부분 함수적 종속성
- 해당 릴레이션의 일부 결정자를 사용해도 1가지 값으로 결정할 수 있는 경우 부분 함수적 종속성
- 일부 결정자를 써도 함수적으로 종속하는 경우
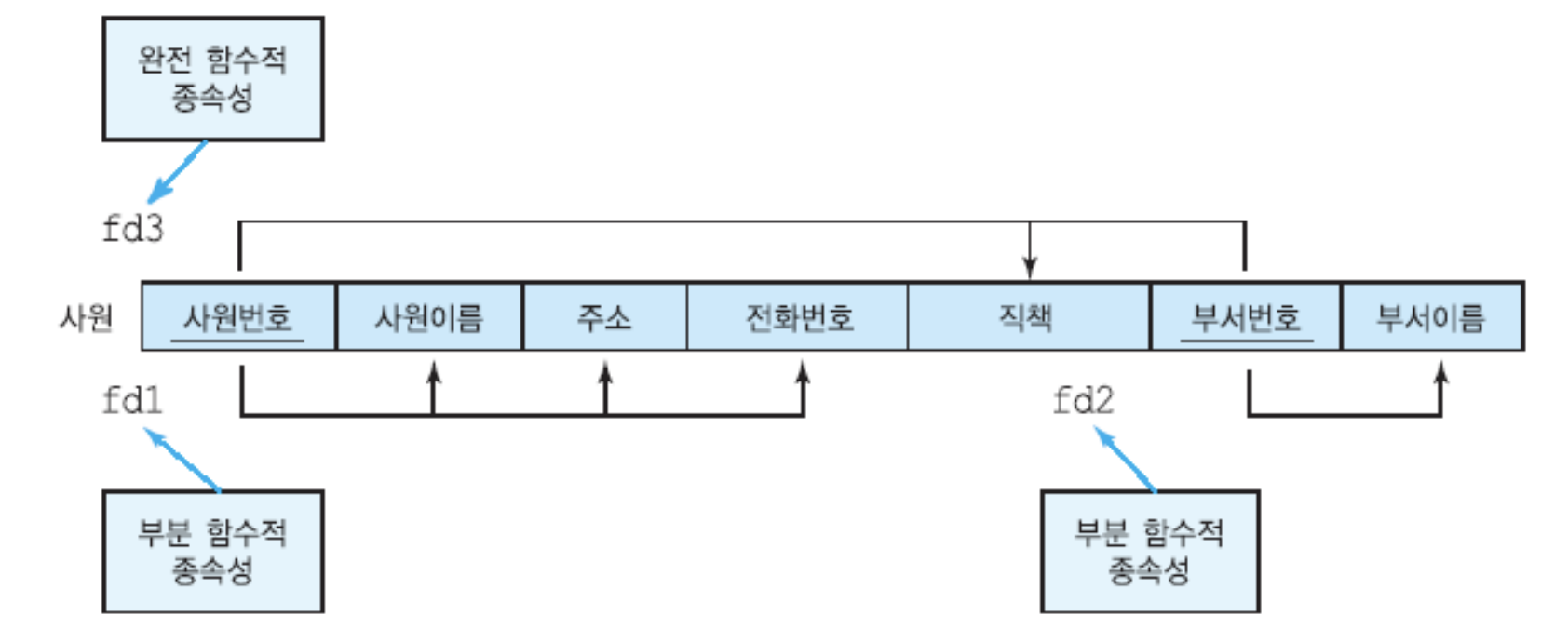
- 이행적 함수적 종속성
- A가 B를 결정하고 B가 C를 결정하는 식으로, 한다리 걸쳐서 종속하는 경우
- A가 B,C를 결정하고 B가 C를 결정하는 식으로 직접 종속과 이행적 종속을 동시에 만족할 수도 있음.

정규화 하기
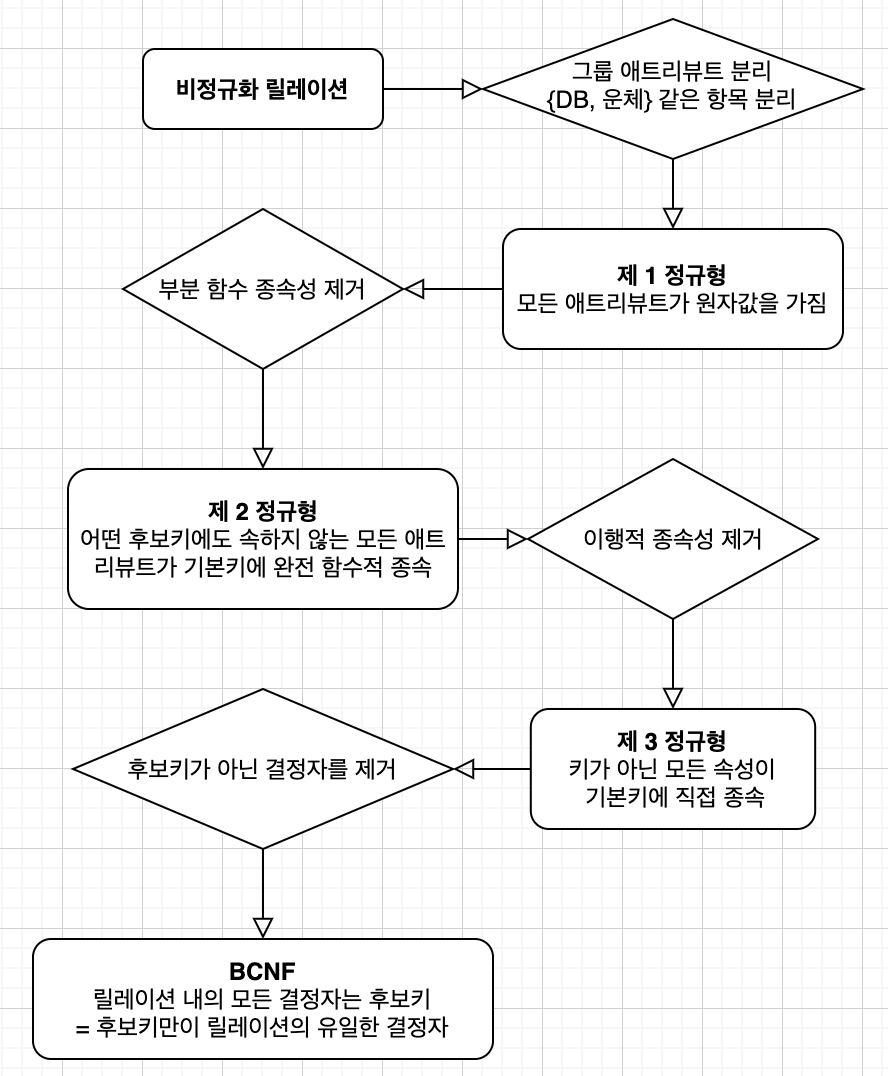
역정규화
- 정규화 수준이 높아질 때 마다 테이블 분리가 일어나므로, DB 설계 자체는 중복과 갱신이상이 적어지게 되지만
- 테이블이 분리되면서 JOIN 필요성이 늘어나니까, 성능 상의 관점에서나 쿼리 가독성의 관점에서는 좋지 않을 수 있음.
- 그래서 요구사항에 따라 적당한 정규화 수준을 선택하는게 중요!
- 경우에 따라서는 역정규화 해서 합쳐버리는 경우도 있다.
- 하지만... 역정규화는 정말 신중하게 접근해야 한다. 역정규화 하는게 더 나은 경우가 거의 없다.(지금은 그래보여도 나중에 문제가 될 소지가 크다.)
- 예를 들어 매입사를 역정규화 해서 컬럼으로 넣어버린다고 했을 때... 다른 곳에서 발급사를 이용해 매입사를 찾는 경우가 발생하지 않을까?를 꼭 생각해보아야 한다. (사용처가 2-3개 이상이 될 가능성이 있는가? 대부분의 경우 yes다.)
- 그런 케이스가 하나라도 발생하면 결국 발급사-매입사 매핑 테이블이 생기게되고, 매입사는 매핑 테이블에서도 관리되고, 역정규화 테이블에서도 이중으로 관리되어야 한다.
- 이렇게 되면 갱신이상 발생할 가능성이 크다. 관리포인트 늘어나서 좋지 않다.
테이블 설계할 때, 절대로 바뀔일이 없는 테이블인지? 를 생각해 보는 것이 중요하다.
수수료 테이블, 자주 바뀌지 않는다고 해서
“결제건과 수수료ID를 조합하면 수수료율 나오니까 중복을 줄이기 위해 trade 테이블에 저장하지 않는다.” 라고 설계한 경우.
갑자기 x일 기준으로 수수료율을 변경해야 한다면,
"x일 이전에는 수수료율 얼마, x일 이후에는 수수료율 얼마" 라는 정보를 어딘가에 추가로 저장해야 한다.
따라서 바뀔 수 있는 테이블을 참조하는 경우,
- 아예 처음 설계할 때 부터 수수료 테이블에 데이터의 유효기간(21.01~22.01)을 컬럼으로 두거나,
- 아니면 trade 테이블에 저장할 때 수수료율도 같이 저장한다. 중복이라 생각할 수 있으나 바뀔 수 있는 정보를 저장하는 것은 중복이 아니다.
정규화 관점에서는 전자가 나을 수 있는데 날짜를 보고 수수료를 조회해야 하니 비즈니스 로직은 조금 더 복잡해진다.
이렇듯 어떤 방법이든 장단이 있으므로 비즈니스 상황에 맞게 결정하면 된다.
'RDBMS > DB Basics' 카테고리의 다른 글
| DB 이중화 / 클러스터링 (0) | 2020.09.23 |
|---|---|
| [DB] 분산 DB, 파티셔닝 (partitioning ), 샤딩 (sharding) (4) | 2019.08.25 |
| 6장. 물리적 데이터베이스 설계 : 인덱스 기본 원리 (0) | 2018.04.06 |
| 5장. 데이터베이스 설계와 ER 모델 (0) | 2018.01.07 |