인공신경망 ( ANN ) #6-3 최적화 : 오버피팅 방지( weight decay, droupout ) / 하이퍼파라미터 최적화
오버피팅( Overfitting )
- 매개변수가 많고 표현력이 높은 모델인 경우
- 훈련 데이터가 적은 경우
Regularization
weight decay ( L2 regularization )
 에 대해 계산한 값을 모두 합산해서 손실 함수에 더한다.
에 대해 계산한 값을 모두 합산해서 손실 함수에 더한다. 을 더하는게 왜 가중치에 페널티를 부과하는 결과를 가져오냐면,
을 더하는게 왜 가중치에 페널티를 부과하는 결과를 가져오냐면,이를 더했기 때문에 오차역전파를 통해 계산한 기울기에 위 항을 미분한 
이에 따라서 가중치 W 갱신이 
 를 더하는 sparsity( L1 regularization )도 있으며 L1, L2 regularization을 동시에 사용할 수 있다.
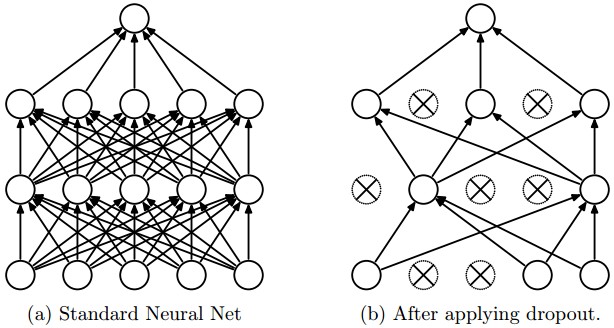
를 더하는 sparsity( L1 regularization )도 있으며 L1, L2 regularization을 동시에 사용할 수 있다. Dropout
하이퍼파라미터 최적화
하이퍼파라미터 최적화는 대략적인 범위를 설정하고 그 범위에서 무작위로 값을 선택해 정확도를 평가한 다음 좋은 정확도를 내는 곳으로 범위를 축소하는 방식을 반복한다.
어느정도 범위가 좁아지면 그 범위 내에서 값을 하나 골라낸다.
* gird search 같은 규칙적 탐색 보다는 무작위로 샘플링해 탐색하는 것이 좋은 결과를 낸다고 한다.
범위는 보통 10의 거듭제곱 단위로 지정한다. 이를 로그 스케일(log scale)로 지정한다고 한다.
딥러닝 학습에는 시간이 오래 걸리기 때문에 학습을 위한 에폭을 작게 하여 1회 평가에 걸리는 시간을 단축하는 것이 효과적이다.
이런 방법 말고, 수학적 이론을 기반으로 한 하이퍼파라미터 최적화 방법으로는 Bayesian optimization이 있다.
practical-bayesian-optimization-of-machine-learning-algorithms.pdf
데이터 확장 (data augmentation)
훈련 이미지의 개수가 적을 때, 이미지를 회전하거나 이동, pixel shift하는 등 미세한 변화를 주어 훈련 데이터의 수를 늘리는 방법.
간단하지만 효과가 꽤나 좋아서 훈련 데이터가 부족할 때 사용하면 좋다.
전이 학습 (transfer learning)
미리 학습된 가중치를 초깃값으로 설정한 다음 새로운 데이터를 대상으로 재학습하는 것.
참고
밑바닥부터 시작하는 딥러닝
http://aikorea.org/cs231n/neural-networks-2-kr/
https://jamesmccaffrey.wordpress.com/2017/02/19/l2-regularization-and-back-propagation/
http://www.cs.toronto.edu/~rsalakhu/papers/srivastava14a.pdf - dropout
'Machine Learning > Theory' 카테고리의 다른 글
| 딥러닝 ( DL, Deep Learning ) / 심층 신경망 ( DNN ) (0) | 2017.03.29 |
|---|---|
| 합성곱 신경망 ( CNN, Convolutional Neural Network ) (11) | 2017.03.27 |
| 인공신경망 ( ANN ) #6-2 최적화 : 초기 가중치 설정, 기울기 소실( gradient vanishing ), 배치 정규화 ( batch normalization ) (0) | 2017.03.25 |
| 인공신경망 ( ANN ) #6-1 최적화 : 가중치 최적화 기법 (0) | 2017.03.24 |
| 인공신경망 ( ANN ) #5 오차역전파법(backpropagation) (2) | 2017.03.20 |